The history
Even disruptive research tools created as recently as 10years ago, and yet fundamental to improving human interactions with information and computers, are susceptible to the onslaught of cyber security threats that exist today! Sometimes, all that the research fraternity needs is access to small amounts of skilled engineers (both crowd sourced and research software engineers) to make the small changes needed to keep such research infrastructure robustly safe. For community focused research the longevity of the solution is very important. Yet, the research prototypes quite often use open source software which if not updated can attract some security risks.
The technical team at R@CMon is staying vigilant to ensure the research prototypes produced as a result of the research projects can stay usable and useful to the communities even after the research part of the projects were completed. A good example of such an impactful, long research prototype Breast Cancer Knowledge Online which survived many years of use thanks to the hard work of the researchers supported by the R@CMon team.
Professor Frada Burstein, Department of Human Centred Computing, Monash Data Futures Institute, Victorian Heart Institute (VHI)
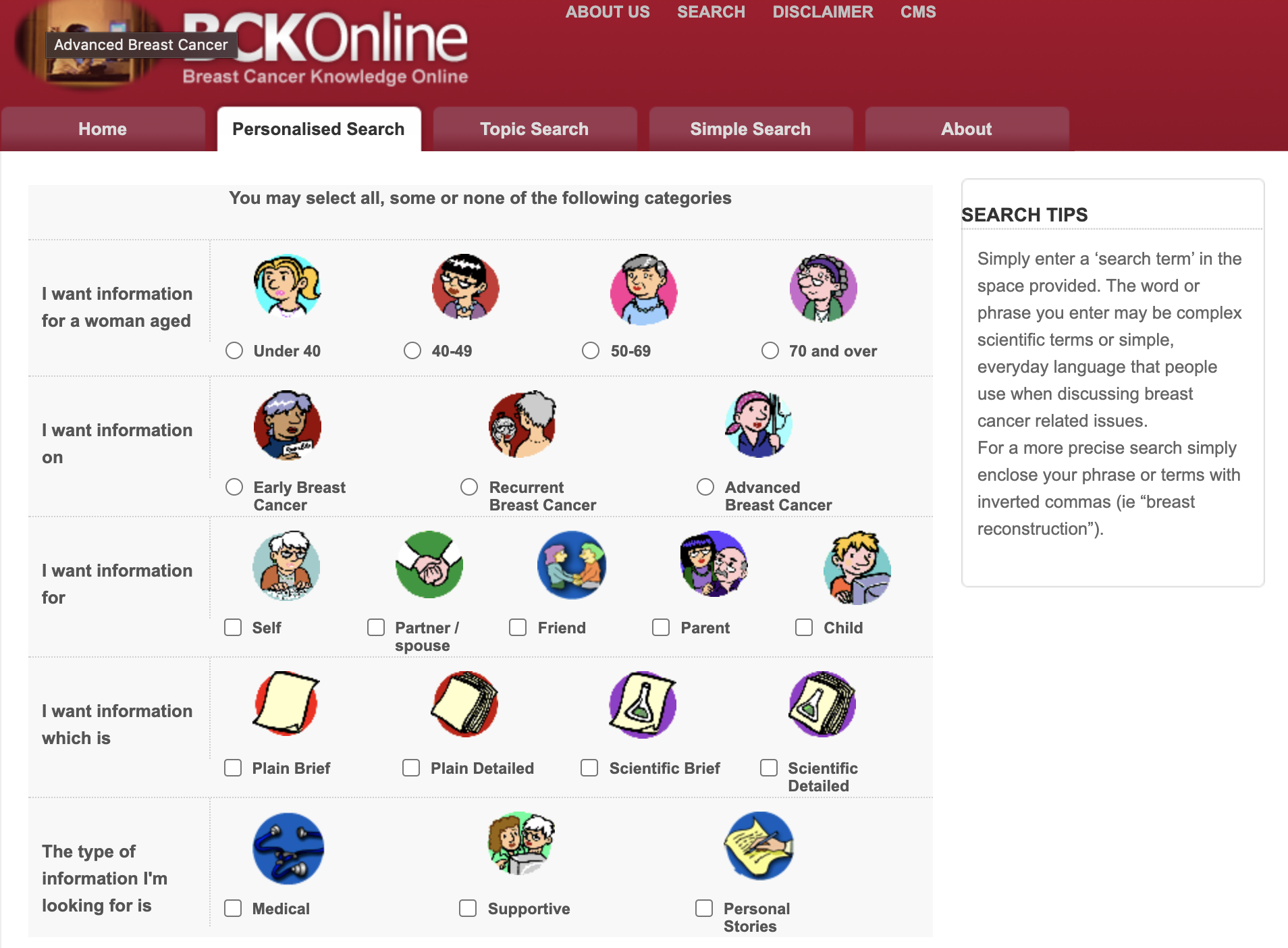
The Monash Faculty of IT initiative led by Professors Frada Burstein and Sue McKemmish in collaboration with BreastCare Victoria and the Breast Cancer Action Group developed a comprehensive online portal of information pertinent to those facing serious health issues related to breast cancer. This work was supported by Australian Research Council and philanthropic funding (Linkage Grant (2001-2003), Discovery (2006-2009), Telematics Trust (2010, 2012), and the Helen Macpherson Smith Trust (2011), resulting in three consecutive implementation efforts of the unique smart health information portal. The full project team is listed on the portal’s “Who We Are” page. The research focussed on the role of personalised searching and retrieval of information, where for example, the needs and preferences of women with breast cancer and their families change over the trajectory of their condition. In contrast a web search bar 10 years ago was generic with very little situational awareness about the person who is searching. The resultant tool, Breast Cancer Knowledge Online (BCKOnline), empowers the individual user to determine the type of information which will best suit her needs at any point in time. The BCKOnline portal uses metadata-based methods to present users with a quality score for data from other public resources carefully curated by breast cancer survivors and other well informed domain experts. The portal’s metadata descriptions of information resources also describe resources in terms of attributes like Author, Title, and Subject. A summary of the information resource and a quality report is also provided. The quality report provides information on where the information came from and who wrote it so the woman can decide if she ‘trusts’ the source.
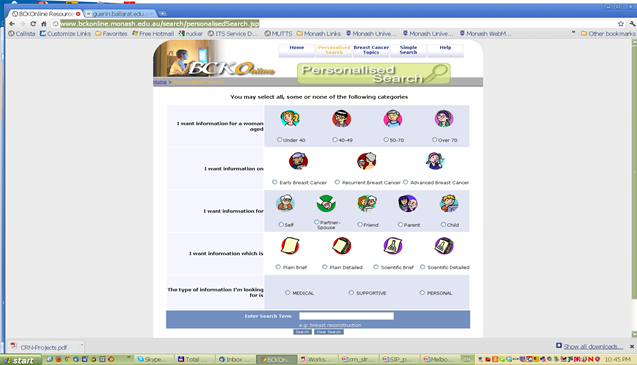
The underlying technical infrastructure of the portal is utilising open source solutions and has been released to the public in two distinct versions (see Figure 1a and 1b for the interfaces for the personalised search for BCKOnline).
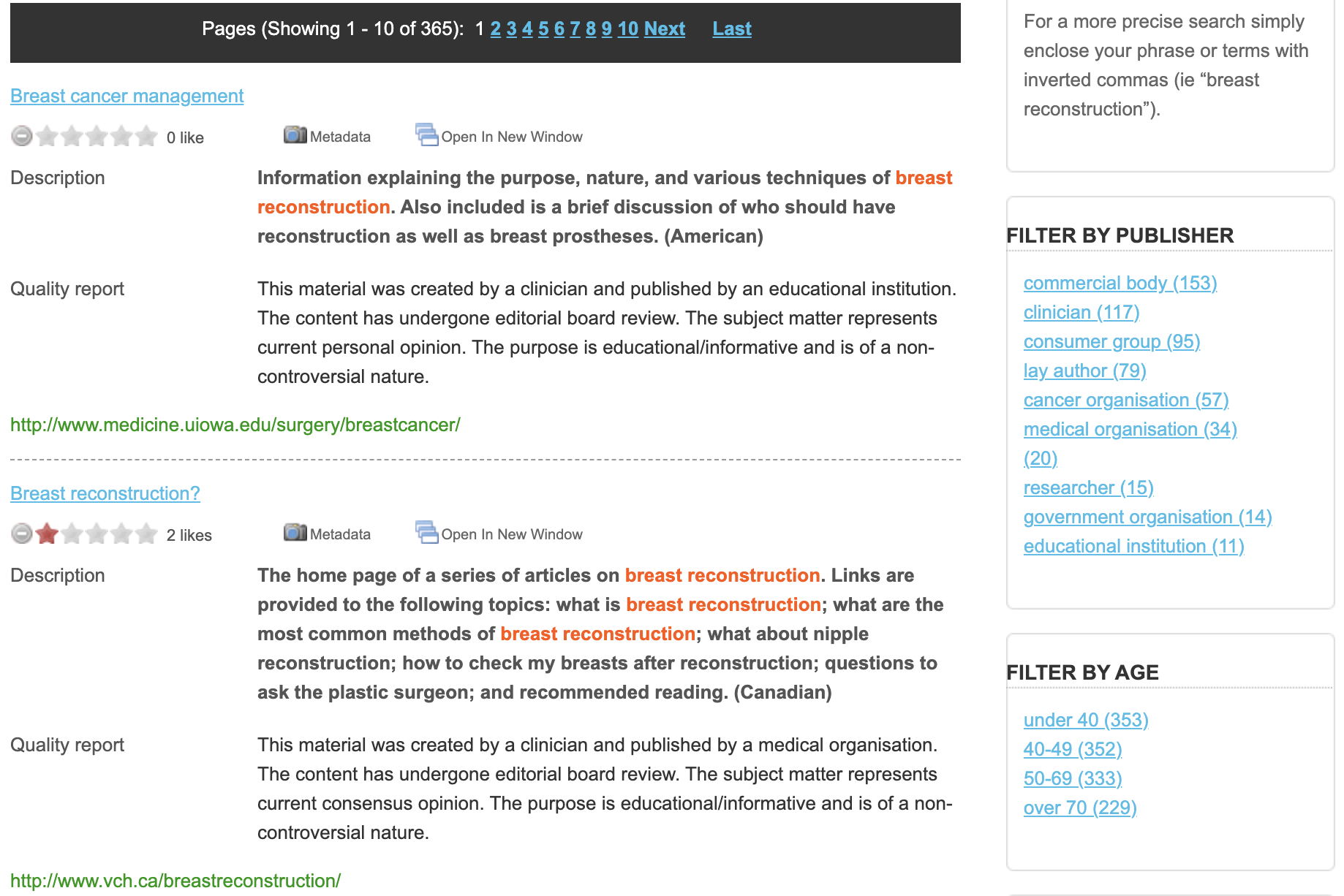
The 2009 paper 1 describes the solution as a paradigm shift in quality health information provision sharing, specifically for women and their families affected by breast cancer. BCKOnline has been used for over 100K+ personalised searches across its over 1K curated quality resources. It has been a valuable resource to teach information management students about the process and value of metadata cataloging. More about this research can be found in these papers 2 3 4 5 6 7 8.
The search results page example is shown in Figure 2 below.
A few years later
Nine years on (in 2019) the maintainers of BCKOnline led by Dr Jue (Grace) Xie, who’s PhD was also connected to the portal development, reached out to the Research Cloud at Monash team (R@CMon), seeking assistance to migrate BCKOnline from its legacy infrastructure to a modern cloud environment and contemporary security controls. Through the ARDC Nectar Research Cloud [2], a new hosting server was deployed for the revamped BCKOnline. Our team walked Frada and Grace through the standard operating procedure to migrate the application to its new home on the research cloud, where Frada and her team have full transparency and control over the application’s lifecycle. The revamped BCKOnline includes a host of security best practices for digital research infrastructure, such as a long term support operating system and proper SSL termination in the web server.
Another step in security best practices for research applications
Recently, the Monash University Cyber Risk & Resilience (CISO’s office) and our teams embarked on a journey to uplift the security profile of all applications on our Research Cloud infrastructure. It is a strategic step change in the University’s expectations regarding security best practices. In partnership with Bugcrowd the Research Cloud at Monash participates in the Vulnerability Disclosure Program (VDP), where all applications are regularly scanned for active threats and vulnerabilities. Bugcrowd are novel in that they vet what is essentially a crowd-sourced team of cyber security engineers. When vulnerabilities are indeed identified, we kick in with a standard operating procedure that is cognisant of research practice and culture to address the issues. This procedure includes end-to-end communication and coordination between the security team, the Research Cloud team and the affected service owners (the chief investigators).
In a recent security scan, we discovered that the BCKOnline portal was vulnerable to “Cross Site Scripting (XSS)”, a method often used by bad actors to conduct attacks like phishing, temporary defacements, user session hijacking, possible introduction of worms etc. Typically these vulnerabilities are quick to fix for a research group (a handful of hours or at most days), and our evidence suggests researchers are motivated to fix them quickly to ensure their systems stay both alive and reputedly safe.
Fixing this vulnerability was complicated by commonplace research realities. The original developers were no longer available (the PhD students had long moved on). The source code to the impacted part of the application was not within a version control system. After some time and a bit of detective work, the R@CMon team managed to recover the original source and upload it into a private GitLab. With that complexity solved, the next step was to apply a fix for the XSS vulnerability. Realising the R@CMon DevOps team didn’t have the expertise nor capacity to fix the problem, we attempted to outsource the problem to professional contractors. However, after two false attempts a new approach was taken. The R@CMon team reached out to another team within the Monash eResearch Centre. The Software Development (SD) team brings with them an extensive array of software development expertise and best practices, including DevOps and security practices, which have been vital assets for this software engineering activity. We effectively crowd-source this remediation work to the team (where individuals pick which cases work for them, and they are appropriately rewarded for work they do in their own time).
Simon Yu, a veteran developer within the software development team pinpointed the actual source of the vulnerability in the code. He then quickly implemented a fix by creating a custom “filter” and “interceptor”. The resultant fix is efficient in both its load on the computing resource and its ability to protect other parts of the BCKOnline application with little/no research effort. Now any incoming requests (e.g user input, searches) will pass through the filter and interceptor first, validating its payload before being processed by the BCKOnline search engine. This ensures that only legitimate payloads are processed. We additionally placed the BCKOnline portal URL (https://bckonline.erc.monash.edu/) behind a web application firewall (WAF) managed by the Monash Cyber Risk and Resilience team. This provides an additional layer of security as all incoming traffic (payloads) are first sanitised by the WAF before forwarding it to the actual server. The original security advisory has since been resolved and the BCKOnline portal is back serving the online community with their personalised health searches.
This article can also be found, published created commons here 9.