Over the past year the Monash NeCTAR porting programme has worked with Griffith University eResearch developers on their Computational Resource Framework (CRF) project. We’re well overdue to promote their excellent work (and a little of ours), and as there will be a presentation on this at eResearch Australasia (A RESTful Web Service for High Performance Computing based on Nimrod/G), now seems a good time to blog about it!
The CRF aims to address one of the long-standing issues in HPC, that is uptake by non-technical users. HPC is a domain with a well-entrenched command-line ethos, unfortunately this does alienate a large cohort of potential users, and that has negative implications for research productivity and collaboration. At Monash, our HPC specialists go to a great deal of effort to ease new users into the CLI (command line interface) environment, however, this is a labour-intensive process that doesn’t catch everybody and often leaves users reliant on individual consultants or team-members.
For some time portals have been the go-to panacea for democratising HPC and scientific computing, and there are some great systems being deployed on the RC, but they still seem to require a large amount of development effort to build and typically cater to a particular domain. Another common issue with “job-management” style portals (including Nimrod’s own ancient CGI beauty) is that they expose and delegate too much information and responsibility to the end user – typically an end user who doesn’t know, or want to know, about the intricacies of the various computational resources. Such mundanities as what credentials they need, which ones are actually working today, etc.
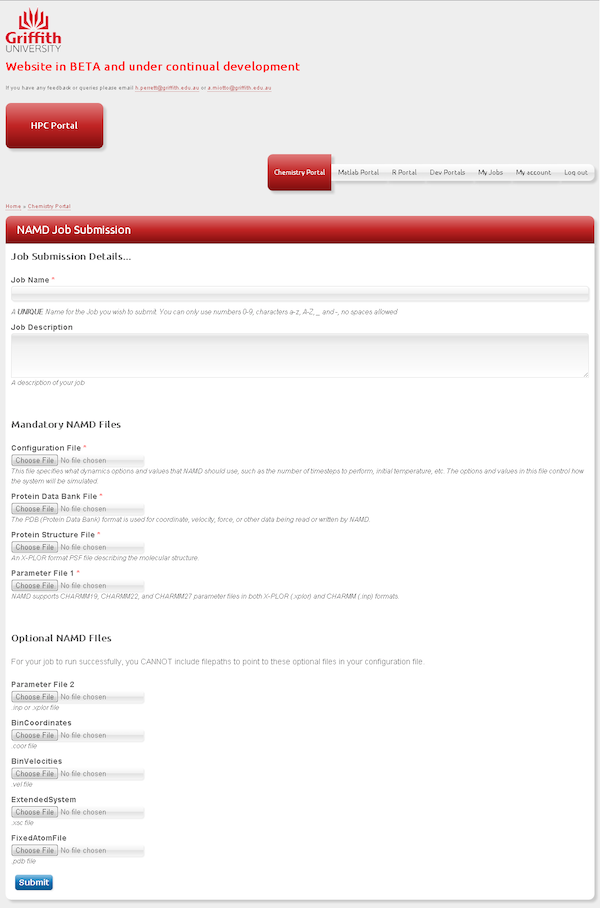
The CRF is different in this respect as it is not a domain-specific interface, instead the Griffith team have taken the approach of concentrating on a minimum set of functionality for some popular HPC and scientific computing applications. The user just inputs info relevant to the application and the CRF configuration determines where and how the job is run. Currently there are UIs for creating, submitting and managing NAMD, R and MATLAB jobs and sets thereof; AutoDock, Octave and Gaussian are in the works. They’ve put a bunch of effort into building out a web-service in front of Nimrod/G, that layer means their UIs are fairly self-contained bits of php that present an interface and translate inputs into a template Nimrod experiment. The web-service has also enabled them to build some other cool bits and pieces, like experiment submission and results over email.
Using Nimrod/G as the back-end resource meta-scheduler means the CRF can intermingle jobs over the local cluster and burst or overflow into the NeCTAR Research Cloud, and that’s the focus of the Monash & Griffith collaboration for this project. We’re now looking to implement scheduling functionality that will make it possible to put simple policies on resources, e.g., use my local cluster but if jobs don’t start within 30 mins then head to the cloud. There should be some updates following in that area after the eResearch conference!