At the start of 2017, the R@CMon team had its first user consultation with Dr. Sri Ramarathinam, a research fellow from the Immunproteomics Laboratory (Purcell Laboratory) at the School of Biomedical Sciences in Monash University. Sri and his group at the lab studies metabolomics compounds in various samples by conducting a “search” and “identification” process using a pipeline of analysis and visualisation tools. The lab has acquired the license to use the commercial XCMSPlus metabolomics platform from SCIEX on their workflow. XCMSPlus provides a powerful solution for analysis of untargeted metabolomics data in a stand-alone configuration, which will greatly increase the lab’s capacity to analyse more samples, with faster and easeful results generation and interpretation.

XCMSPlus main login Page, entry point of the complete metabolomics platform
During the first engagement meeting with Sri and the lab, it’s been highlighted that a specialised hosting platform (with appropriate storage and computational capacity) would be required for XCMSPlus. XCMSPlus is distributed as stand-alone appliance (personal cloud) from the vendor. As an appliance, XCMSPlus has been optimised and packaged to be deployed on a single, multi-core and high-memory machine. An added minor complication is that this appliance was distributed in VMWare’s appliance format, which need to be translated into an OpenStack-friendly format. The R@CMon team provided the hosting platform required for XCMSPlus through the Monash node of the Nectar Research Cloud.
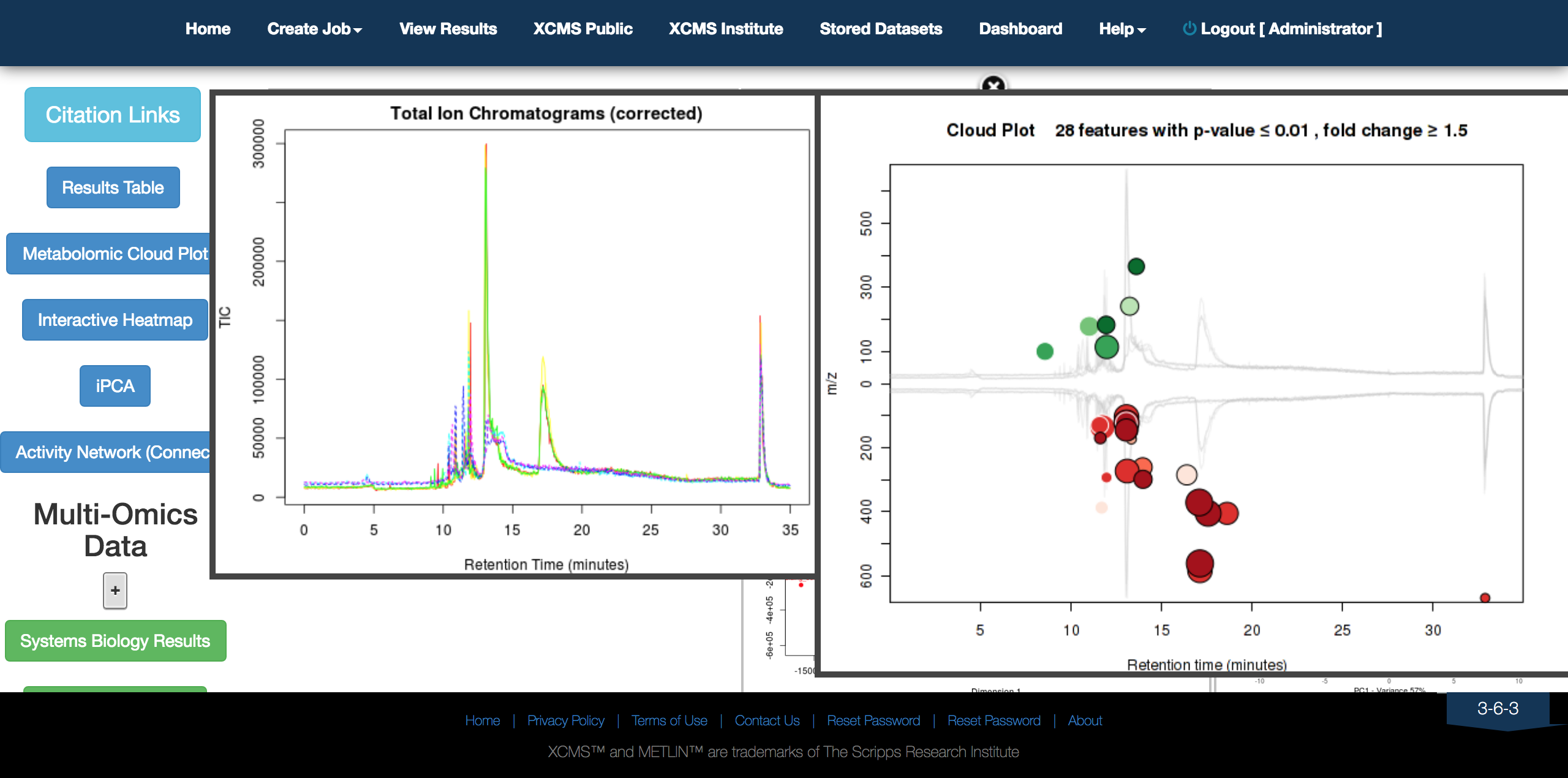
Analysis results and visualisation in XCMSPlus
A dedicated Nectar project has been provisioned for the lab, which is now being used for hosting XCMSPlus. This project also has enough capacity for future expansion and new analysis platform deployments. The now R@CMon-hosted (and supported) XCMSPlus platform for the Immunproteomics Laboratory is the first custom XCMSPlus deployment in Australia. Due to being the first in Australia, there were some early minor issues encountered during its first test runs. These technical issues were eventually sorted out due to collaborative troubleshooting efforts from the R@CM team, the lab and the vendor. And after several months of usage, hundred of jobs submitted and processed by XCMSPlus, and counting, the lab is continuing to fully integrate it as part of their analysis workflow. The R@CMon team is actively engaging with the lab for supporting its adaption of XCMSPlus and planning for future analysis workflow expansions.