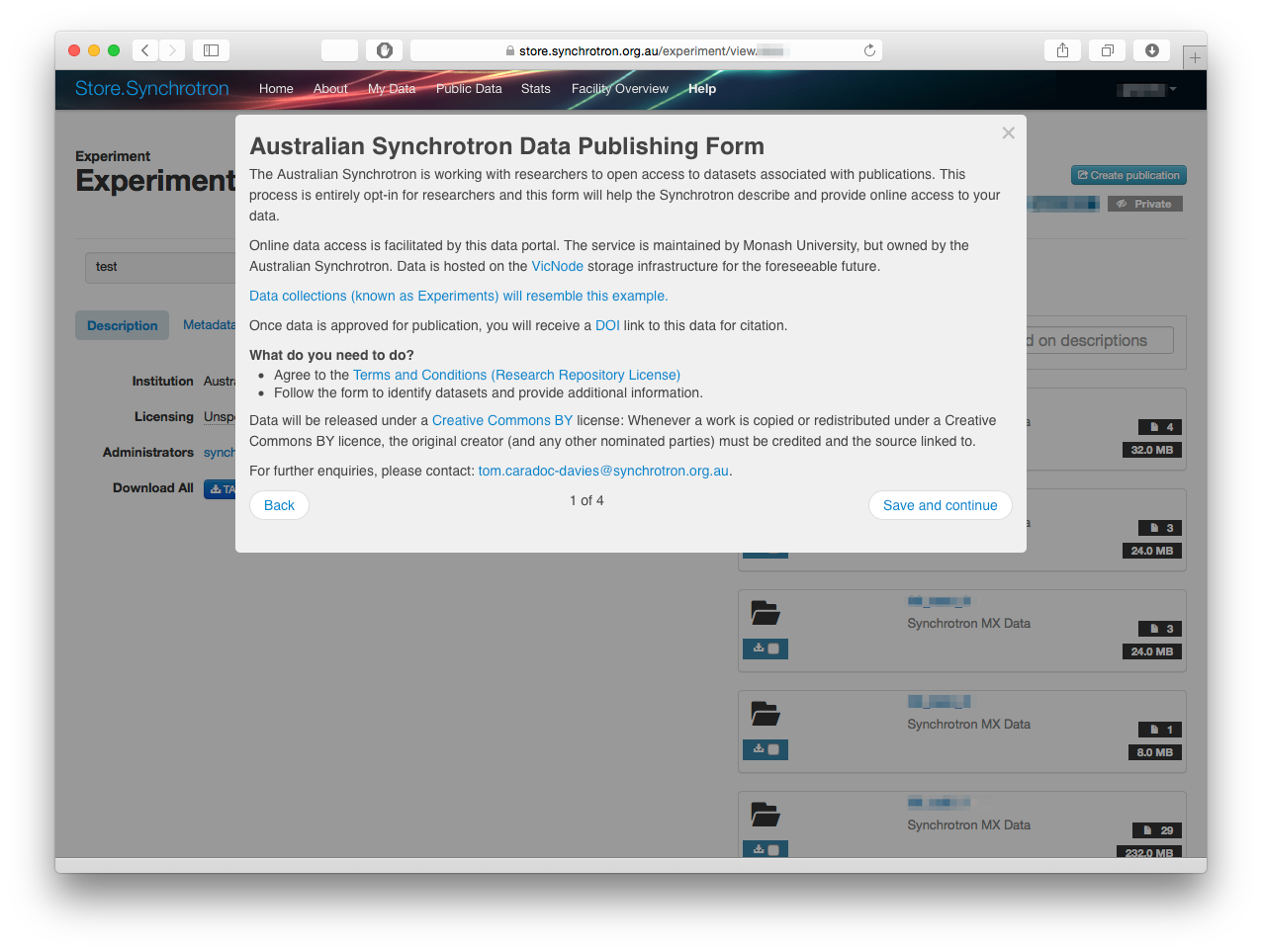
Ceph is our favourite software defined storage system here at R@CMon, underpinning over 2PB of research data as well as the Nectar volume service. This post provides some insight into the one of the many operational aspects of Ceph.
One of the many structures Ceph makes use of to allow intelligent data access as well as reliability and scalability is the Placement Group or PG. What is that exactly? You can find out here, but in a nutshell PGs are used to map pieces of data to physical devices. One of the functions associated with PGs is ‘scrubbing’ to validate data integrity. Let’s look at how to check the status of PG scrubs.
Let’s find a couple of PGs that map to osd.0 (as their primary):
[admin@mon1 ~]$ ceph pg dump pgs_brief | egrep '\[0,|UP_' | head -5 dumped pgs_brief PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY 57.5dcc active+clean [0,614,1407] 0 [0,614,1407] 0 57.56f2 active+clean [0,983,515] 0 [0,983,515] 0 57.55d8 active+clean [0,254,134] 0 [0,254,134] 0 57.4fa9 active+clean [0,177,732] 0 [0,177,732] 0 [admin@mon1 ~]$
For example, the PG 57.5dcc has an ACTING osd set [0, 614, 1407]. We can check when the PG is scheduled for scrubbing on it’s primary, osd.0:
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.5dcc"))'
{
"pgid": "57.5dcc",
"sched_time": "2018-04-11 06:17:39.770544",
"deadline": "2018-04-24 03:45:39.837065",
"forced": false
}
[root@osd1 admin]#
Under normal circumstances, the sched_time and deadline are determined automatically by OSD configuration and effectively define a window during which the PG will be next scrubbed. These are the relevant OSD configurables:
[root@osd1 admin]# ceph daemon osd.0 config show | grep scrub | grep interval "mon_scrub_interval": "86400", "osd_deep_scrub_interval": "2419200.000000", "osd_scrub_interval_randomize_ratio": "0.500000", "osd_scrub_max_interval": "1209600.000000", "osd_scrub_min_interval": "86400.000000", [root@osd1 admin]# [root@osd1 admin]# ceph daemon osd.0 config show | grep osd_max_scrub "osd_max_scrubs": "1", [root@osd1 admin]#
What happens when we tell the PG to scrub manually?
[admin@mon1 ~]$ ceph pg scrub 57.5dcc instructing pg 57.5dcc on osd.0 to scrub [admin@mon1 ~]$
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.5dcc"))'
{
"pgid": "57.5dcc",
"sched_time": "2018-04-12 17:09:27.481268",
"deadline": "2018-04-12 17:09:27.481268",
"forced": true
}
[root@osd1 admin]#
The sched_time and deadline have updated to now, and forced has changed to ‘true’. We can also see the state has changed to active+clean+scrubbing:
[admin@mon1 ~]$ ceph pg dump pgs_brief | grep '^57.5dcc' dumped pgs_brief 57.5dcc active+clean+scrubbing [0,614,1407] 0 [0,614,1407] 0 [admin@mon1 ~]$
Since the osd has osd_max_scrubs configured to 1, what happens if we try to scrub another PG, say 57.56f2:
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.56f2"))'
{
"pgid": "57.56f2",
"sched_time": "2018-04-12 01:45:52.538259",
"deadline": "2018-04-25 00:57:08.393306",
"forced": false
}
[root@osd1 admin]#
[admin@mon1 ~]$ ceph pg deep-scrub 57.56f2
instructing pg 57.56f2 on osd.0 to deep-scrub
[admin@mon1 ~]$
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.56f2"))'
{
"pgid": "57.56f2",
"sched_time": "2018-04-12 17:11:37.908137",
"deadline": "2018-04-12 17:11:37.908137",
"forced": true
}
[root@osd1 admin]#
[admin@mon1 ~]$ ceph pg dump pgs_brief | grep '^57.56f2'
dumped pgs_brief
57.56f2 active+clean [0,983,515] 0 [0,983,515] 0
[admin@mon1 ~]$
The OSD has updated sched_time, deadline and set ‘forced’ to true as before. But the state is still only active+clean (not scrubbing), because the OSD is configured to process a max of 1 scrub at a time. Soon after the first scrub completes, the second one we initiated begins:
[admin@mon1 ~]$ ceph pg dump pgs_brief | grep '^57.56f2' dumped pgs_brief 57.56f2 active+clean+scrubbing+deep [0,983,515] 0 [0,983,515] 0 [admin@mon1 ~]$
You will notice after the scrub completes, the sched_time is again updated. The new timestamp is determined by the osd_scrub_min_interval (1 day) and osd_scrub_interval_randomize_ratio (0.5). Effectively, it randomizes the next scheduled scrub between 1 and 1.5 days since the last scrub:
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.56f2"))'
{
"pgid": "57.56f2",
"sched_time": "2018-04-14 02:37:05.873297",
"deadline": "2018-04-26 17:36:03.171872",
"forced": false
}
[root@osd1 admin]#
What is not entirely obvious is that a ceph pg repair operation is also a scrub op and lands in the same queue of the primary OSD. In fact, a pg repair is a special kind of deep-scrub that attempts to fix irregularities it finds. For example, lets run a repair on PG 57.5dcc and check the dump_scrubs output:
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.5dcc"))'
{
"pgid": "57.5dcc",
"sched_time": "2018-04-14 03:43:29.382655",
"deadline": "2018-04-26 17:18:37.480484",
"forced": false
}
[root@osd1 admin]#
[admin@mon1 ~]$ ceph pg dump pgs_brief | grep '^57.5dcc'
dumped pgs_brief
57.5dcc active+clean [0,614,1407] 0 [0,614,1407] 0
[admin@mon1 ~]$ ceph pg repair 57.5dcc
instructing pg 57.5dcc on osd.0 to repair
[admin@mon1 ~]$ ceph pg dump pgs_brief | grep '^57.5dcc'
dumped pgs_brief
57.5dcc active+clean+scrubbing+deep+repair [0,614,1407] 0 [0,614,1407] 0
[admin@mon1 ~]$
[root@osd1 admin]# ceph daemon osd.0 dump_scrubs | jq '.[] | select(.pgid |contains ("57.5dcc"))'
{
"pgid": "57.5dcc",
"sched_time": "2018-04-13 16:02:58.834489",
"deadline": "2018-04-13 16:02:58.834489",
"forced": true
}
[root@osd1 admin]#
This means if you run a pg repair and your PG is not immediately in the repair state, it could be because the OSD is already scrubbing the maximum allowed PGs so it needs to finish those before it can process your PG. A workaround to get the repair processed immediately is to set noscrub and nodeep-scrub, restart the OSD (to stop current scrubs), then run the repair again. This will ensure immediate processing.
In conclusion, the sched_time and deadline from the dump_scrubs output indicate what could be a scrub, deep-scrub, or repair while the forced value indicates if it came from a scrub/repair command.
The only way to tell if next (automatically) scheduled scrub will be a deep-scrub is to get the last deep-scrub timestamp, and work out if osd_deep_scrub_interval will have passed at the time of the next scheduled scrub:
[admin@mon1 ~]$ ceph pg dump | egrep 'PG_STAT|^57.5dcc' | sed -e 's/\([0-9]\{4\}\-[0-9]\{2\}\-[0-9]\{2\}\) /\1@/g' | sed -e 's/ \+/ /g' | cut -d' ' -f1,21
dumped all
PG_STAT DEEP_SCRUB_STAMP
57.5dcc 2018-03-18@03:29:25.128541
[admin@mon1 ~]$
In this case, the last scrub was almost exactly 4 weeks ago, and the osd_deep_scrub_interval is 2419200 seconds (4 weeks). By the time the next scheduled scrub comes along, the PG will be due for a deep scrub. The dirty sed command above is due to the pg dump output having irregular spacing and spaces in the time stamp 🙂