The Ramialison Group at the Australian Regenerative Medicine Institute (ARMI) located in the biomedical research precinct of Monash University, Clayton specialises in systems biology both on the bench and through computational analysis. Their work is driven by the in vivo and in silico dissection of regulatory mechanisms involved in heart development, where deregulation of such mechanisms cause congenital heart disease, which results in 1 out of every 100 babies to be born with heart defects in Australia.
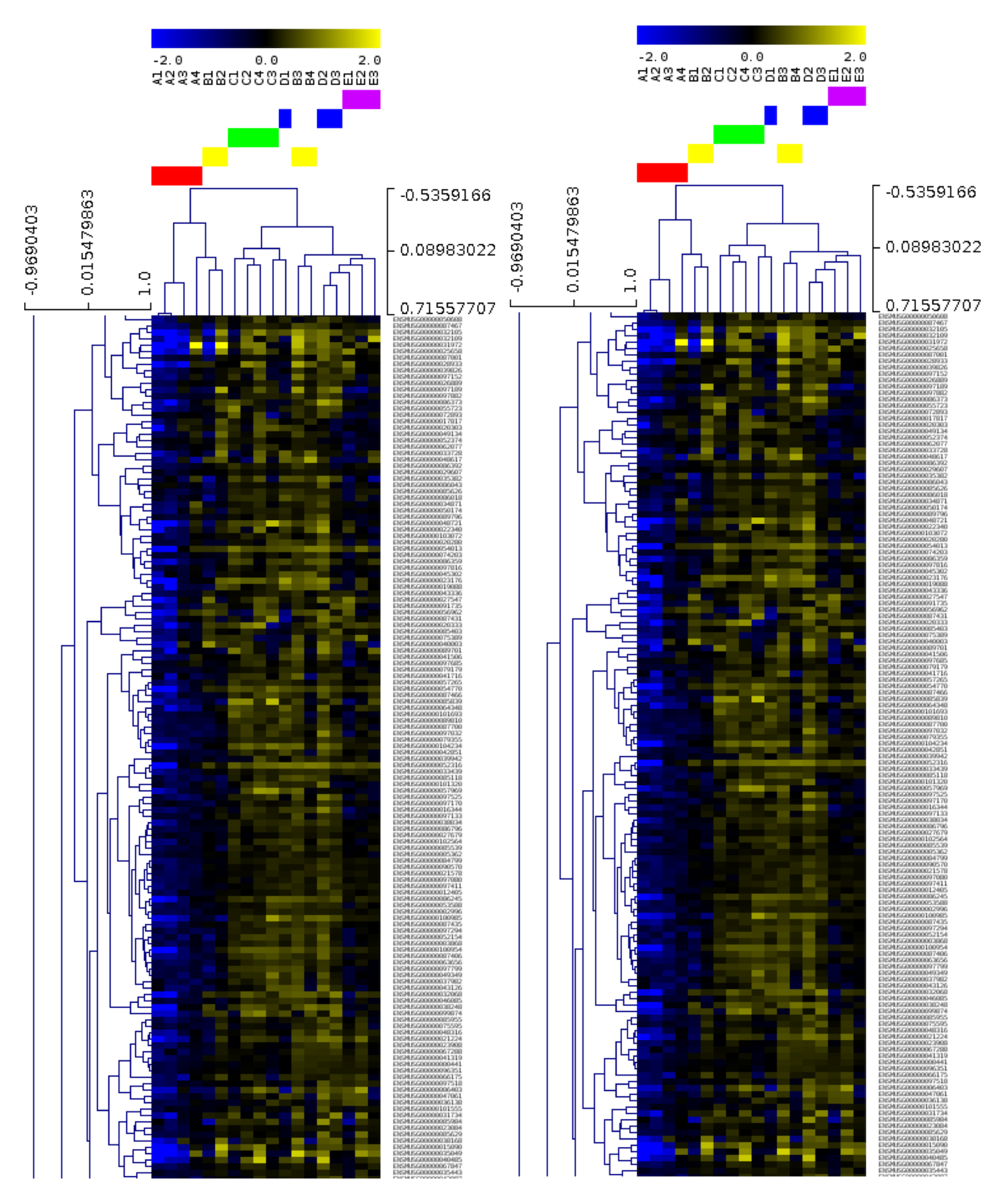
Heatmap generated from transcriptomic data from heart samples (Nathalia Tan)
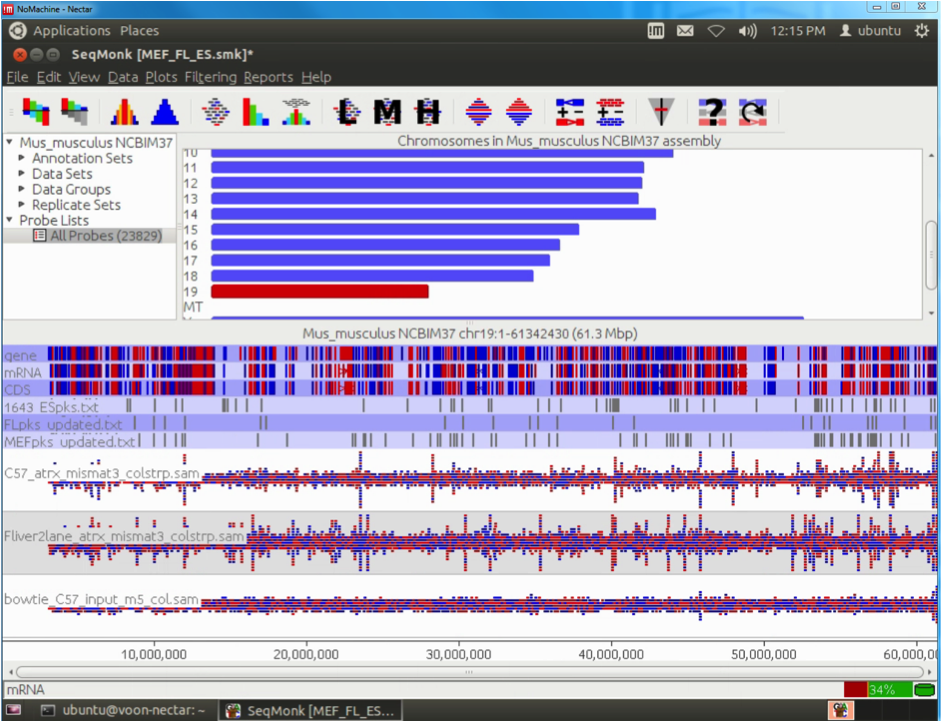
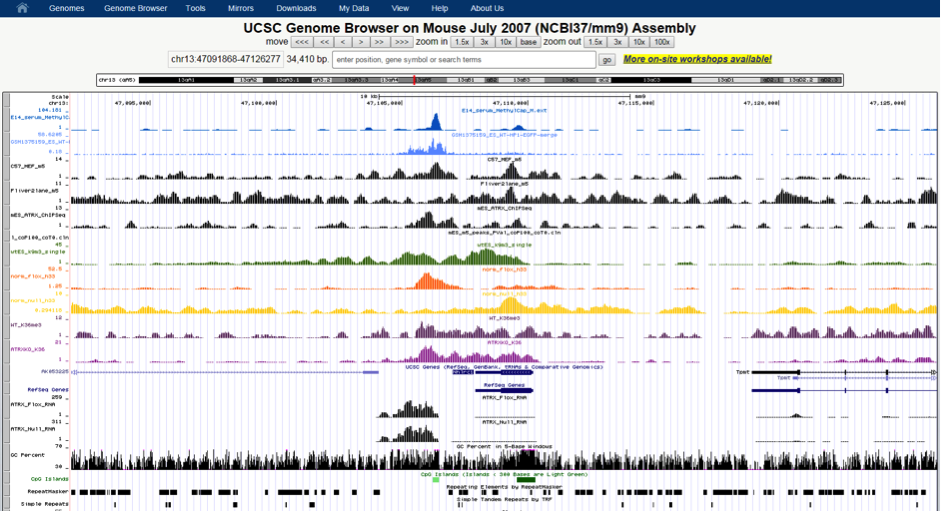
Their research focuses on identifying DNA elements that play a crucial role in the development of the heart and, that could be impaired in disease. To identify these sequences, several genome-wide interrogation technologies (genomics and transcriptomics) are employed on different model organisms such as mouse or zebrafish. Downstream analysis of the data generated from these experiments involves high performance computing and requires large storage, which can be up to hundreds of gigabytes in size for a single project.
To optimise their investigation into heart development, the R@CMon team has deployed a dedicated Decoding Heart Development and Disease (DHDD) server on the Monash node of the NeCTAR Research Cloud infrastructure, which has now been running for over a year. This has not only provided the group with faster processing speeds in comparison to running jobs on a local desktop, but also an appropriate file storage infrastructure with persistent storage for files that are regularly accessed during analysis. Through VicNode, the group has been given vault storage for archiving completed results for their various research projects. With the assistance R@CMon, the group has been able to easily add users to the server as it continues to grow with new members and local collaborators.

Web interface for the Trawler web service.
In addition to the DHDD server, the R@CMon team also assisted the Ramialison Group in deploying a dedicated cloud server that has been used to develop the Trawler motif discovery tool web service. The implementation of this tool allows the group to quickly and easily analyse next-generation sequencing data and identify overrepresented motifs, which has led to a manuscript that is currently in preparation. The Ramialison Group envisage future developments of similar simple and easy to use bioinformatics analysis tools through R@CMon.