Simon Campbell, Research Fellow from the Faculty of Science, Monash University has been running large-scale 3D stellar hydrodynamics parallel calculations on the Magnus super computing facility at iVEC and Raijin, the national peak facility at NCI. These calculations aim to improve 1D modelling of the core helium burning (CHeB) phase of stars using a novel multi-dimensional fluid dynamics approach. The improved models will have significant impact on many fields of astronomy and astrophysics such as stellar population synthesis, galactic chemical evolution and interpretation of extragalactic objects.
The parallel calculations generate raw data dumps (heavy data) containing several scalar variables, which are pre-processed and converted into HDF5. A custom script is used to extract the metadata (light data) into XDMF format, a standard format used by HPC codes and recognised by various scientific visualisation applications like ParaView and VisIt. The stellar data are loaded into VisIt and visualised using volume rendering. Initial volume renderings were done on a modest dual core laptop using just low resolution models (200 x 200 x 100, 106 zones). It’s been identified that applying the same visualisation workflow on high resolution models (400 x 200 x 200, 107 zones and above), would require a parallel (MPI) build of VisIt running on a higher performance machine.
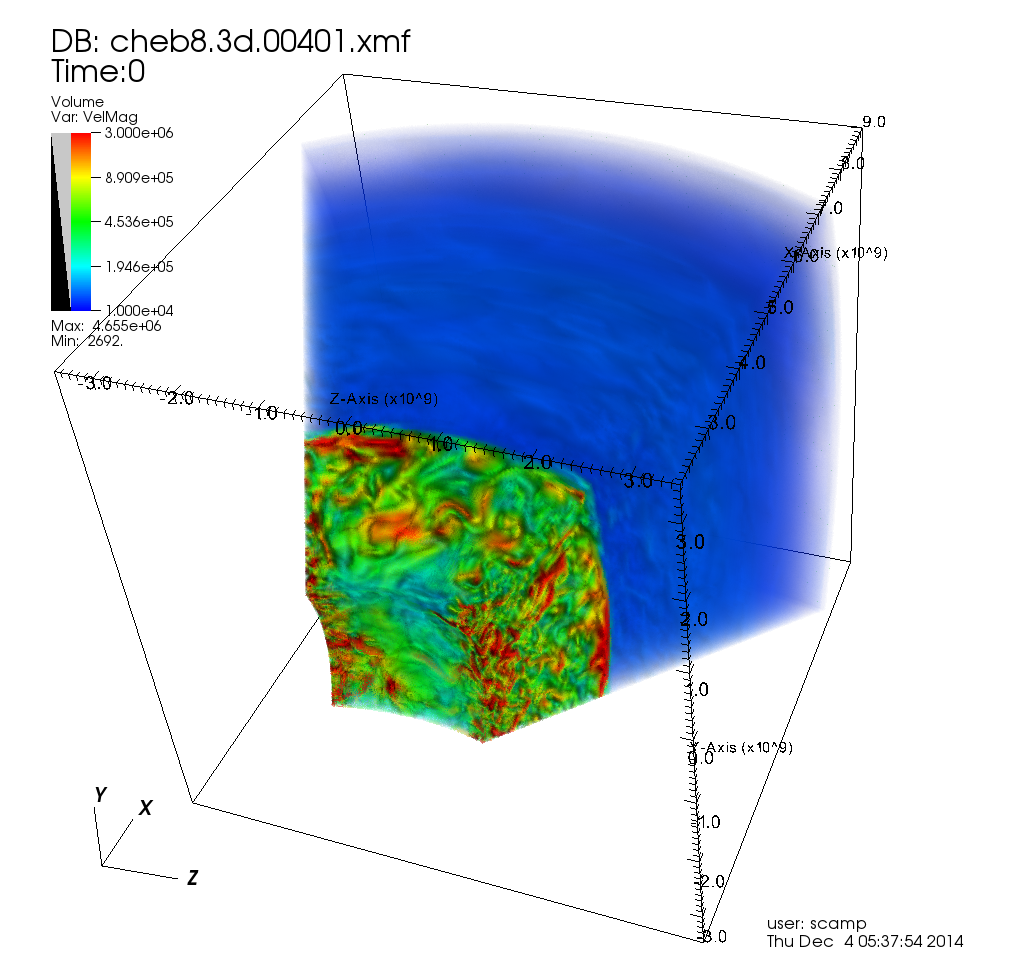
Snapshot of turbulent convection deep inside the core of a star that has a mass 8 times that of the Sun. Colours indicate gas moving at different velocities. Volume rendered in parallel using VisIt + MPI.
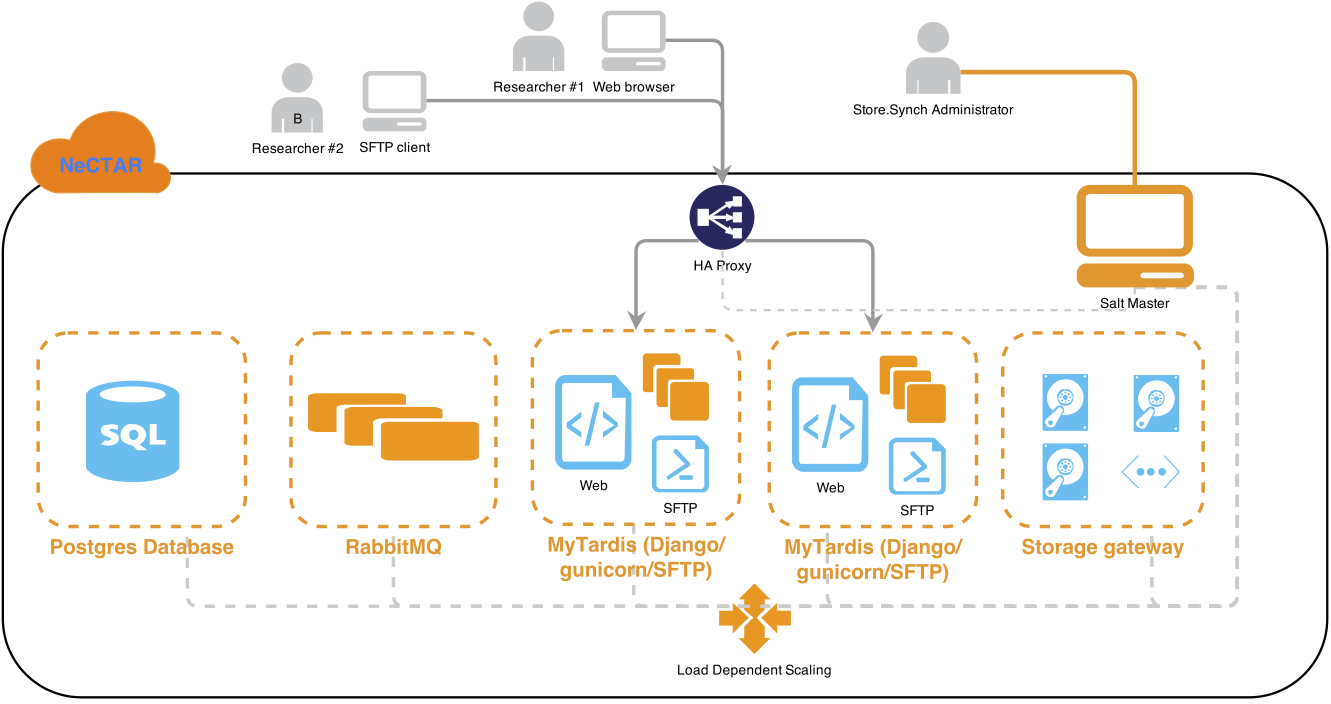
R@CMon Phase 2 to the rescue! The timely release of R@CMon Phase 2 provided the required computational grunt to perform these high resolution volume renderings. The new specialist kit in this release includes hypervisors housing 1TB of memory. The R@CMon team allocated a share (~50%, ~460GB of memory) on one of these high memory hypervisors to do the high resolution volume renderings. Persistent storage on R@CMon Phase 2 is also provided on the computational instance for ingestion of data from the supercomputing facilities and generation of processing and rendering results. VisIt has been rebuilt on the high-memory instance, this time with MPI capabilities and XDMF support.
Initial parallel volume rendering using 24 processes shows a ~10x speed-up. Medium (400 x 200 x 200, 107 zones) and high-resolution (800 x 400 x 400, 108 zones) plots are now being generated using the high-memory instance seamlessly, and an even higher resolution (1536 x 1024 x 1024, 109 zones) simulation is currently running on Magnus. The resulting datasets from this simulation, which are expected to be several hundred gigabytes in size, will then be put in the same parallel volume rendering workflow.